
QuantRocket 2.9.0 is now available. This release brings improvements to the JupyterLab code editor, an expanded and enhanced Pipeline API, improvements to Alphalens, and other enhancements. See how to update.
Highlights
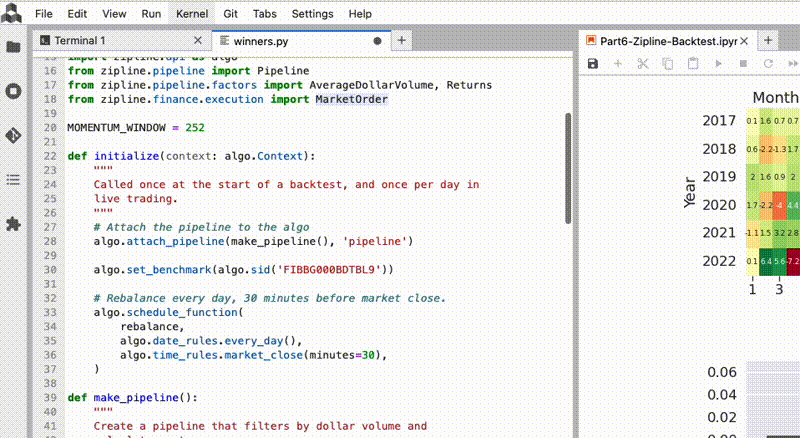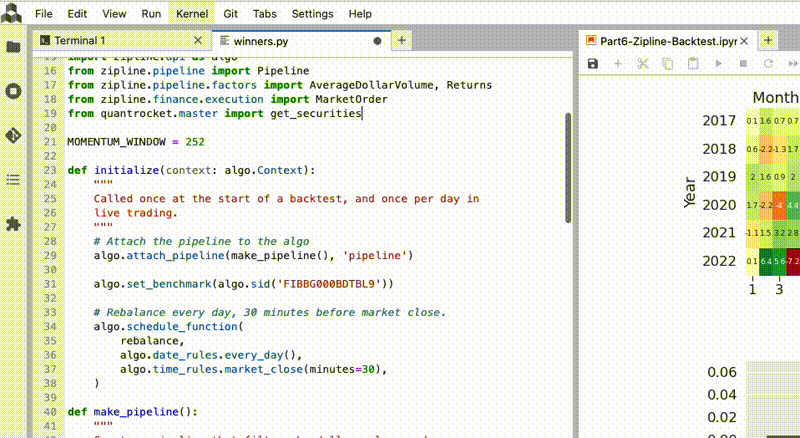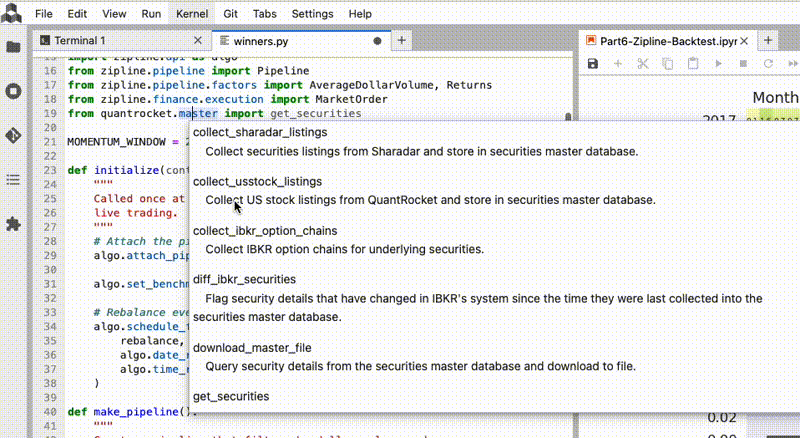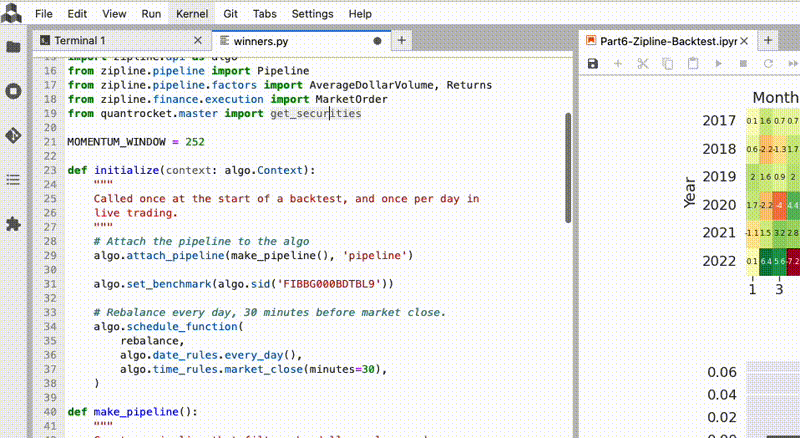
- JupyterLab code editing: Greatly improved code completion and hover documentation in Jupyter Notebooks and the JupyterLab text editor. Pyright, Microsoft's static type checker and language server used in Visual Studio Code, is now integrated into QuantRocket. JupyterLab's text editor, which was previously too basic to be useful, can now be used for writing and editing code. See the QuickStart in JupyterLab for a demonstration of the new features.
-
Pipeline: The Pipeline API has received numerous enhancements, including: new "periodic" factors for performing arbitrary rolling computations on Sharadar fundamental data (such as 5-year dividend growth); several pre-built fundamental factors like Piotroski F-Score; a new Pipeline dataset for borrow fees; new Factor methods like
where(),shift(), andfillna()to make the Pipeline API more similar to the pandas API; the ability to create scores from Factors; and more. See the Zipline section below for more details. -
Alphalens: To support the many Pipeline enhancements, Alphalens now provides a new function,
from_pipeline(), which allows you to easily generate a tear sheet directly from a Pipeline definition, eliminating the boilerplate code that was previously required. This function also supports segmented analysis (like segmented backtests in Moonshot) which makes it possible to create Alphalens tear sheets for long date ranges that are too large to fit in memory. See the Alphalens section below for more details. - IB Gateway: Automatic retries of IB Gateway two-factor authentication for live accounts. When QuantRocket attempts to log in to IB Gateway for an account with two-factor authentication, a notification will be sent to your mobile device. If you do not acknowledge the mobile notification within 3 minutes, QuantRocket will stop and restart IB Gateway to trigger a new notification being sent. This process will repeat indefinitely until you eventually acknowledge a notification. See the usage guide.
API Changes
- The Pipeline dataset
zipline.pipeline.data.ibkr.ShortableSharesnow queries shortable shares aggregate daily data (for the previous day) rather than querying intraday shortable shares. The new approach is more suitable for Pipeline since Pipeline is designed for returning prior day, end-of-day data. Due to this change, the dataset columns have changed toMinQuantity,MaxQuantity,MeanQuantity, andLastQuantity, and thetimedimension is no longer applicable. See the usage guide. - The data granularity of the Interactive Brokers borrow fees dataset has changed from intraday to daily. This change is motivated by the fact that borrow fees are only assessed on overnight positions, meaning that intraday granularity does not provide value while making the data more voluminous and harder to work with. For more information, see the usage guide.
Users who previously collected intraday borrow fees should perform the following one-time process. First, from a JupyterLab terminal, delete the old borrow fees database:
$ rm /var/lib/quantrocket/quantrocket.v2.fundamental.ibkr.stockloan.fees.sqlite
Then, from a terminal on the host machine, restart the fundamental service to re-create the empty database:
$ docker compose restart fundamental
Then collect the borrow fees data for the countries that interest you.
- The zipline
Universefilter (zipline.pipeline.filters.master.Universe) has been renamed toStaticUniverseand moved tozipline.pipeline.filters.StaticUniverse. The old name is still available for backwards-compatibility. See the usage guide. - The endpoint for collecting Reuters financial statements from the IBKR API (
quantrocket.fundamental.collect_reuters_financials/quantrocket fundamental collect-reuters-financials) has been removed. This data is no longer available from IBKR. The endpoints for querying the data from your local database (quantrocket.fundamental.download_reuters_financials/quantrocket fundamental reuters-financialsandquantrocket.fundamental.get_reuters_financials_reindexed_like) have been retained so that users who previously collected Reuters financial statements can continue querying the data. - Eclipse Theia has been removed. Theia was previously provided as a code editor because the JupyterLab text editor was too basic to be useful. Now that the JupyterLab text editor supports auto-complete and hover documentation, the Theia integration is obsolete.
alphalens:2.9.0
- a new function
from_pipeline(...)allows you to generate a full Alphalens tear sheet from a pipeline object. This function includes asegmentparameter (modeled on segmented backtests in Moonshot) which allows you to analyze large date ranges that contain too much data to fit in memory. See the usage guide. - Alphalens tear sheets have received several enhancements and new plots, including plots depicting top and bottom quantile composition by group when using the
groupbyparameter. See Lecture 38 of the Quant Finance Lectures for a walk-through.
quantrocket/fundamental:2.9.0
- The IBKR shortable shares dataset is now provided at aggregated daily granularity in addition to the original 15-minute intraday granularity. The aggregated data is less voluminous and thus easier to work with over large universes of securities. Intraday data can continue to be used to accurately model the availability of shortable shares at the time of trade. See the usage guide.
- The IBKR borrow fees dataset is now stored at daily granularity instead of the previous intraday granularity. See the fuller explanation in the API Changes section above.
quantrocket/houston:2.9.0
- fix an issue where cloud deployments might not auto-renew their SSL certificates depending on what time of day they were originally deployed
quantrocket/ibg:2.9.0
- Automatic retries of two-factor authentication for live accounts. When QuantRocket attempts to log in to IB Gateway for an account with two-factor authentication, a notification will be sent to your mobile device. If you do not acknowledge the mobile notification within 3 minutes, QuantRocket will stop and restart IB Gateway to trigger a new notification being sent. This process will repeat indefinitely until you eventually acknowledge a notification. See the usage guide.
- update to IB Gateway 10.19
quantrocket/jupyter:2.9.0
- Greatly improved code completion and hover documentation in Jupyter Notebooks and the JupyterLab text editor. Pyright, Microsoft's static type checker and language server used in Visual Studio Code, is now integrated into QuantRocket. JupyterLab's text editor, which was previously too basic to be useful, can now be used for writing and editing code. See the QuickStart in JupyterLab for a demonstration of the new features.
quantrocket/license-service:2.9.0
- add retry to license service requests to avoid errors when the license service is temporarily unavailable. See related forum post.
quantrocket/master:2.9.0
- new securities master fields for Interactive Brokers:
ibkr_StockType(e.g. COMMON, PREFERRED, REIT, ETF, ADR, etc.) and 3 fields related to lot size:ibkr_MinSize,ibkr_SizeIncrement, andibkr_SuggestedSizeIncrement. See the field reference in the usage guide.
quantrocket/postgres:2.9.0
- update to TimescaleDB 2.10.1. TimescaleDB has changed the storage format for aggregate databases in recent versions and will eventually cease supporting the older format. Therefore, users with real-time aggregate databases are advised to drop the aggregate database (not the underlying tick database) and re-create it, which will ensure it uses the new TimescaleDB storage format. If dropping and re-creating the aggregate database is problematic because you have dropped older ticks from the underlying tick database and need to preserve them in the aggregate database, please post in the support forum for assistance with the more complicated process of migrating the old format to the new format.
quantrocket/zipline:2.9.0
- a new set of "periodic" Pipeline factors and filters allow performing computations that utilize fundamental data and involve a lookback window, such as calculating the average dividend per share over the previous 4 quarters. See the usage guide.
- Several new calculated fundamental factors using Sharadar data, including Piotroski F-Score, Altman Z-Score, and Interest Coverage Ratio, have been added to the Pipeline API. See the API Reference.
- A new Pipeline dataset
zipline.pipeline.data.ibkr.BorrowFeesallows loading IBKR borrow fees into Pipeline. See the usage guide. - The Pipeline dataset
zipline.pipeline.data.ibkr.ShortableSharesnow returns aggregated daily shortable shares instead of intraday values. See the fuller explanation in the API Changes section above. - setting a
period_offseton the Pipeline DataSetzipline.pipeline.data.sharadar.Fundamentalsis now optional and defaults to 0 if omitted. See the usage guide. - add an optional
exclude_window_lengthparameter to thezipline.pipeline.factors.Returnsfactor. This allows excluding the most recent data from momentum calculations, as is common in the academic literature. See the API Reference. - a new
.as_factor()method for Pipeline Filters allows casting a Filter (which consists of boolean values) to a Factor consisting of 1s and 0s. An example use case for this functionality is to create numeric scores based on various boolean conditions. See the API Reference. - several methods have been added to Pipeline to make the API more similar to pandas:
-
Factor.fillna(...)(API Reference) andClassifier.fillna(...)(API Reference) allow you to fill empty values with scalars or other factors or classifiers, similar to pandas'.fillna(). -
Factor.where(...)(API Reference) andClassifier.where(...)(API Reference) allow you to replace or ignore values in factors or classifiers based on boolean conditions, similar to pandas'.where(). -
Factor.shift()(API Reference),Filter.shift()(API Reference), andClassifier.shift()(API Reference) allow you to shift values forward, similar to pandas'.shift().
-
- several Pipeline Filters can now be accessed directly as methods from existing Filters or Factors, rather than having to be separately imported:
- Filters such as
AllPresent([EquityPricing.close], window_length=200)can now be written asEquityPricing.close.all_present(200). See the API Reference. - Filters such as
All([EquityPricing.volume.latest > 0], window_length=200)can now be written as(EquityPricing.volume.latest > 0).all(200). See the API Reference. - Filters such as
Any([DailyReturns() > 0.10], window_length=5)can now be written as(DailyReturns > 0.10).any(5). See the API Reference. - Filters such as
AtLeastN([DailyReturns() > 0.10], window_length=10, N=2)can now be written as(DailyReturns > 0.10).at_least_n(2, 10). See the API Reference. - Factors such as
PercentChange([EquityPricing.close], window_length=2)can now be written asEquityPricing.close.latest.pct_change(). See the API Reference.
- Filters such as
- a
symbol()function for looking up assets by ticker symbol has been added. Thesymbolfunction was originally part of Zipline but was removed in a previous release because ticker symbols can change, making it more robust to use thesid()function. However, thesymbol()is convenient and can be appropriate at times, particularly in research notebooks, so it has been restored. See the API Reference for usage in research environments and the usage guide for algorithms. - Fix a design issue that caused Pipeline data to be lagged by two days in daily strategies, instead of one day. Background: Pipeline data is lagged, with today's pipeline output containing yesterday's data. This design makes sense for minute strategies, where pipeline output (containing yesterday's data) is accessed and acted upon in the current trading session (either before trading starts or during the session). However, daily strategies don't run until after the close, which means that any orders that are placed aren't executed until the next day's session. This constitutes a two-day lag: day 1's data shows up in day 2's pipeline output, and resulting orders are executed on day 3 (since they're entered after the close of day 2). To avoid this extra delay, pipeline output in daily mode will now load the current day's data, rather than the prior day's data. Minute strategies are unaffected by this change.
- the Pipeline filter
StaticSidsnow works with QuantRocket sids. (Previously, it expected numeric sids, which are only used internally in Zipline.) See the usage guide.