I have created an installation on EC2 with the commands provided. Now as my backtests are slow, I decided I need more CPU and Memory and I have changed from a t2.large to a t2.xlarge. (Also made the IP static) and now I consider going to t3.xlarge
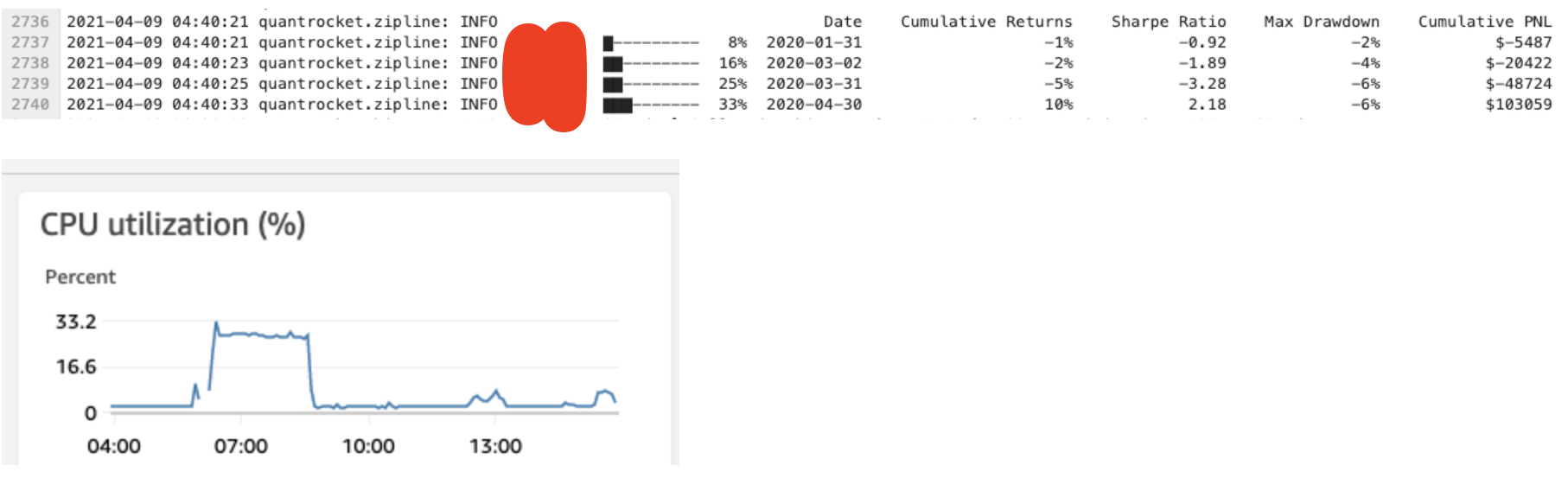
When I look at the CPU usage in EC2 during a backtest it is 30%
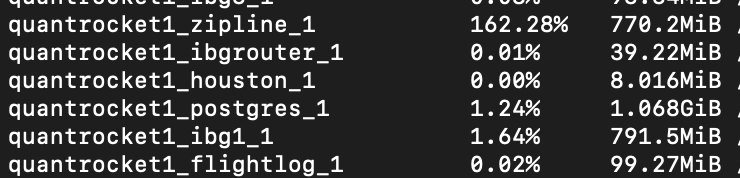
When I run docker stats I see zipline is running 107%.....
When I inspect the docker-machine, I see however that the IP is wrong, the instance still says t2.large.
So my question is: how do I make sure the zipline container use more CPU? If I give it a bigger instance should it start using more after it restarted? or doesn't that matter?
Or does that not work and do I need to set up the whole thing again?
any pointer is appreciated
$ docker-machine inspect quantrocket
{
"ConfigVersion": 3,
"Driver": {
"IPAddress": "XXXXXXXXXX",
"MachineName": "quantrocket",
"SSHUser": "ubuntu",
"SSHPort": 22,
"SSHKeyPath": "/patht/id_rsa",
"StorePath": "/pathr/.docker/machine",
"SwarmMaster": false,
"SwarmHost": "tcp://0.0.0.0:3376",
"SwarmDiscovery": "",
"Id": "312d2cc0d883793608104c6b309411da",
"AccessKey": "XXXXXXXXXXX",
"SecretKey": "XXxxxxXXXXX",
"SessionToken": "",
"Region": "us-east-1",
"AMI": "ami-927185ef",
"SSHKeyID": 0,
"ExistingKey": false,
"KeyName": "quantrocket",
"InstanceId": "i-0aXXXXXXX08088",
"InstanceType": "t2.large",
"PrivateIPAddress": "1xxxxxxx",
"SecurityGroupId": "",
"SecurityGroupIds": [
"sg-0XXXXXXXXe124"
],
"SecurityGroupName": "",
"SecurityGroupNames": [
"docker-machine"
],
"SecurityGroupReadOnly": false,
"OpenPorts": [
"80",
"443"
],
"Tags": "",
"ReservationId": "",
"DeviceName": "/dev/sda1",
"RootSize": 200,
"VolumeType": "gp2",
"IamInstanceProfile": "",
"VpcId": "vpc-XXXXXfe",
"SubnetId": "subnXXXXX3",
"Zone": "a",
"RequestSpotInstance": false,
"SpotPrice": "0.50",
"BlockDurationMinutes": 0,
"PrivateIPOnly": false,
"UsePrivateIP": false,
"UseEbsOptimizedInstance": false,
"Monitoring": false,
"SSHPrivateKeyPath": "",
"RetryCount": 5,
"Endpoint": "",
"DisableSSL": false,
"UserDataFile": ""
},
"DriverName": "amazonec2",
"HostOptions": {
"Driver": "",
"Memory": 0,
"Disk": 0,
"EngineOptions": {
"ArbitraryFlags": [],
"Dns": null,
"GraphDir": "",
"Env": [],
"Ipv6": false,
"InsecureRegistry": [],
"Labels": [],
"LogLevel": "",
"StorageDriver": "",
"SelinuxEnabled": false,
"TlsVerify": true,
"RegistryMirror": [],
"InstallURL": "https://get.docker.com"
},
"SwarmOptions": {
"IsSwarm": false,
"Address": "",
"Discovery": "",
"Agent": false,
"Master": false,
"Host": "tcp://0.0.0.0:3376",
"Image": "swarm:latest",
"Strategy": "spread",
"Heartbeat": 0,
"Overcommit": 0,
"ArbitraryFlags": [],
"ArbitraryJoinFlags": [],
"Env": null,
"IsExperimental": false
},
"AuthOptions": {
"CertDir": "/path/.docker/machine/certs",
"CaCertPath": "/pathr/.docker/machine/certs/ca.pem",
"CaPrivateKeyPath": "/path/.docker/machine/certs/ca-key.pem",
"CaCertRemotePath": "",
"ServerCertPath": "/path/.docker/machine/machines/quantrocket/server.pem",
"ServerKeyPath": "path/.docker/machine/machines/quantrocket/server-key.pem",
"ClientKeyPath": "/path/.docker/machine/certs/key.pem",
"ServerCertRemotePath": "",
"ServerKeyRemotePath": "",
"ClientCertPath": "/path/.docker/machine/certs/cert.pem",
"ServerCertSANs": [],
"StorePath": "/path/.docker/machine/machines/quantrocket"
}
},
"Name": "quantrocket"
my stats:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
d88b64fb5a97 quantrocket_logspout_1 0.17% 8.938MiB / 15.67GiB 0.06% 414kB / 3.1MB 0B / 0B 11
2a3a91f00176 quantrocket_houston_1 0.50% 3.27MiB / 15.67GiB 0.02% 64.1MB / 65.1MB 4.1kB / 4.1kB 3
df36996552d0 quantrocket_blotter_1 0.00% 125.7MiB / 15.67GiB 0.78% 3.53MB / 164kB 0B / 7.96MB 15
b163d3cb6440 quantrocket_realtime_1 0.02% 97.88MiB / 15.67GiB 0.61% 14.1kB / 9.89kB 0B / 0B 29
8f38d4a0c90a quantrocket_history_1 0.00% 75.59MiB / 15.67GiB 0.47% 1.73kB / 0B 0B / 0B 17
22a04fc1d3f2 quantrocket_fundamental_1 0.00% 137.6MiB / 15.67GiB 0.86% 1.96MB / 11.4MB 4.1kB / 65.5kB 13
139d54d48b16 quantrocket_master_1 0.00% 131.5MiB / 15.67GiB 0.82% 1.75MB / 5.18MB 0B / 125MB 13
ae9989b068a8 quantrocket_satellite_1 0.00% 28.06MiB / 15.67GiB 0.17% 9.84kB / 5.83kB 0B / 65.5kB 12
3cfac16831af quantrocket_account_1 0.00% 100.2MiB / 15.67GiB 0.62% 119kB / 111kB 0B / 0B 9
cfbfcc70b4b8 quantrocket_jupyter_1 0.57% 327MiB / 15.67GiB 2.04% 7.27MB / 36.5MB 1.58MB / 20.3MB 36
ac635f62dc0e quantrocket_flightlog_1 0.01% 89.59MiB / 15.67GiB 0.56% 1.6MB / 23.5kB 0B / 0B 25
2d96b151f937 quantrocket_countdown_1 0.02% 60.57MiB / 15.67GiB 0.38% 1.96kB / 169B 27MB / 8.19kB 9
8b65596d02e5 quantrocket_theia_1 0.02% 126.2MiB / 750MiB 16.82% 2.08kB / 0B 0B / 0B 30
52add1ceb52a quantrocket_db_1 0.00% 57.58MiB / 15.67GiB 0.36% 2.08kB / 0B 0B / 0B 6
642758f1da86 quantrocket_zipline_1 101.21% 679.1MiB / 15.67GiB 4.23% 12MB / 2.14MB 0B / 2.2MB 30
adf039b3dbeb quantrocket_moonshot_1 0.00% 106.3MiB / 15.67GiB 0.66% 1.81kB / 0B 0B / 0B 11
e25c320cfcff quantrocket_codeload_1 3.09% 148.1MiB / 15.67GiB 0.92% 2.71MB / 13.9kB 4.1kB / 10.8MB 87
74b6ab58ea19 quantrocket_license-service_1 0.00% 94.78MiB / 15.67GiB 0.59% 1.3MB / 575kB 0B / 0B 5
230e9c48e199 quantrocket_ibgrouter_1 0.00% 31.16MiB / 15.67GiB 0.19% 388kB / 306kB 0B / 0B 5
4474ea1495ed quantrocket_ibg1_1 0.01% 79MiB / 15.67GiB 0.49% 269kB / 173kB 0B / 61.4kB 24
476d182adc2e quantrocket_postgres_1 0.02% 79.98MiB / 15.67GiB 0.50% 11.6kB / 12.2kB 0B / 53.1MB 13
27f629e55671 cloud_moonshot_1 0.01% 106.5MiB / 15.67GiB 0.66% 828B / 0B 1.27MB / 0B 11